Quick Plug
I used this webcrawler to create a dataset of 1,825 Leetcode problems and have made it available for download on kaggle. At the time of this writing, it is the largest, most viewed, and most downloaded LeetCode dataset on the platform.
Disclaimer
Please note that the webcrawler described in this blog post was developed for educational purposes only. It is important to respect the terms of service and copyright of the websites being crawled. It is also important to adhere to the robots.txt file, which specifies any crawling restrictions for a website. This webcrawler should not be used for any commercial or unethical purposes, and the author of this post is not responsible for any damages or legal issues that may arise from the use of this webcrawler.
Background
I was having a conversation with a couple of other software engineers about webcrawling recently and it led me to reflecting on a personal project I worked on a couple of years ago.
During my last job search around this time in 2021, I decided to focus on building up some blind spots in my skillset by learning more about backend and server infrastructure. At that time, I had been building iOS apps with SwiftUI at a mid-sized company for 2.5 years and doing frontend with JavaScript frameworks like React and Angular for 3 years at a small company before that, but felt like my curiosity and interests aligned more with data and backend. I was especially interested in understanding how companies scale to meet the demand of their apps.
I was part of a study group and we would practice algorithms and system design together to prepare for interviews. One minor issue we faced was paralysis by analysis - there's so many LeetCode problems to solve within different problem types, and we didn't always create a plan or have a direction for attacking them.
Aha Moment
So that's when the idea hit me, we should automate this by building a Slackbot that queries LeetCode and build an entire productivity platform around this. I stopped studying algorithms and instead started to study how to build a webcrawler so that I could crawl LeetCode's website and build up the dataset for this project. I felt that if I could get over this hurdle, then building the Slackbot client for this wouldn't be so hard.
Strategy
The overall idea was to make a request to the LeetCode website and parse the html to get all the data I needed to about a problem - name, difficulty, prompt, companies who asked the question, etc. This would be stored in a database and would integrate into Slack in two ways. The first would be auto-posting new questions every Monday after they're released. The second would be to support a user querying the database with a Slack slash command such as "/new", "/airbnb", "/problem_id", etc and format it to look nice with Slack Block Kit.
Choosing The Tech Stack
After building out prototypes in NodeJS, Python, and Go, I realized that Python had the best tooling for the job so I combed through documentation and learned enough Python to be productive. A secondary reason I chose Python was that if I could build datasets with Python, which was essentially similar to tasks in data engineering, then I could use it to learn Data Science. Python is the dominant langauge in the data field, so doing this in NodeJS or Go wouldn't allow me the overlap. It took some time to get used to the syntax, but I found Python very enjoyable to write even though I preferred compiled languages like Swift.
At the time, AWS was the most popular cloud infrastructure provider and it had everything I needed at an affordable price for a hobby project - relational db (RDS), object storage (S3), serverless functions (Lambda), and API management (API Gateway). There was also a lot more documentation on AWS than there was for GCP or Azure, so I figured that this would be the best choice for this project as a new learner.
Architecture
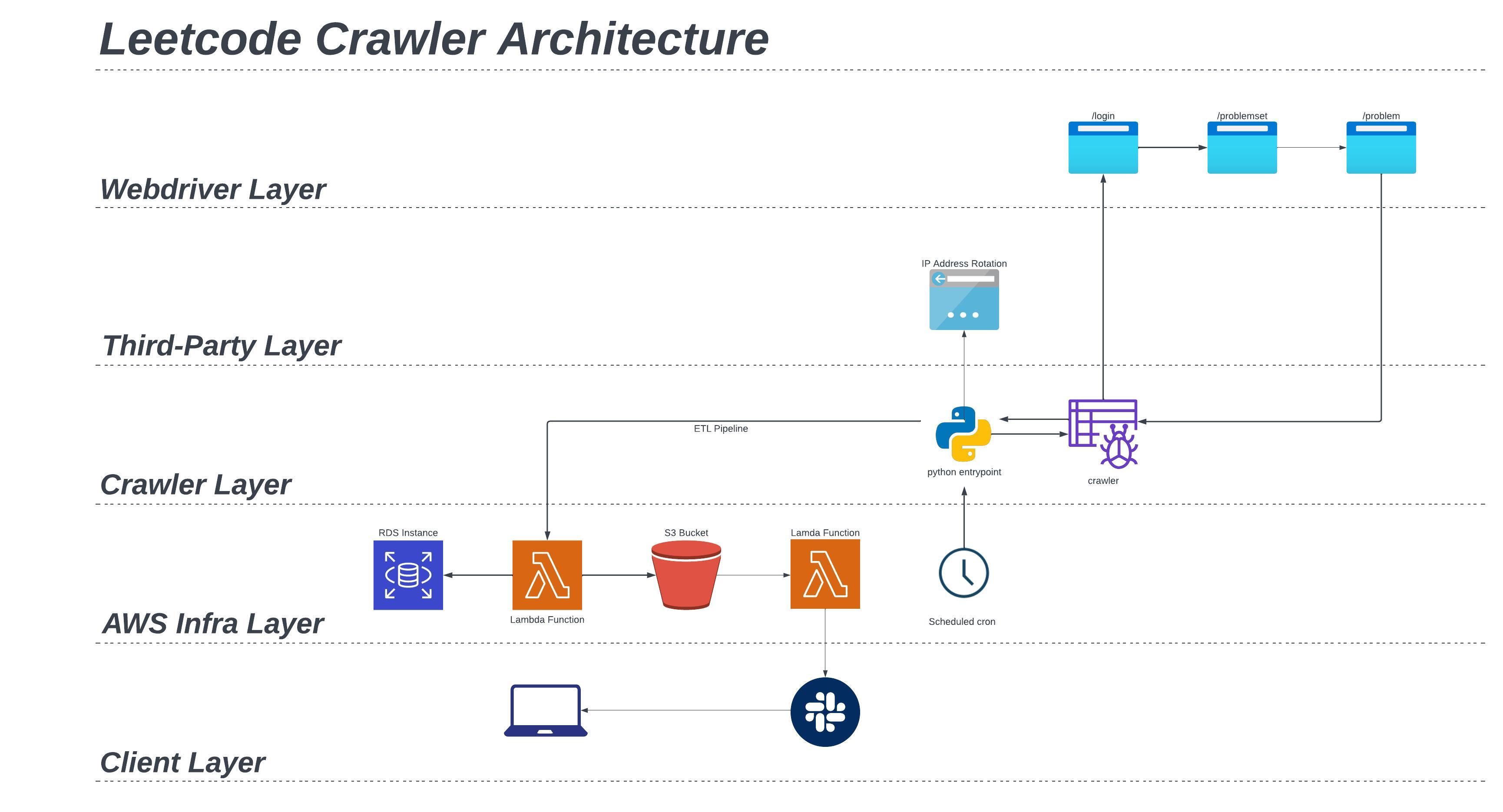
The first part of the architecture is the webcrawler, and is executed as follows:
- Scheduled cron job executes py script
- Generate a random user-agent string and IP address
- Webcrawler logs in with given credentials
- Upon login, navigate to the problem set url
- Parse page for the html parent container with all the problem child nodes
- Navigate to the next available problem url
- Extract all available information
- Expand collapsed menus and extract all available information (e.g., similar problems, companies, etc)
- After data extraction, navigate back to the problem list
- Navigate to the next available problem url and repeat, or paginate to next page
- When all problems and pages have been exhausted, return data to py script
- Clean and transform all data into desired format
- Execute AWS Lambda function to load data in RDS as SQL rows and S3 as CSV file
- Upon S3 object put, auto-trigger AWS Lambda to post a Slack message
- Client gets notification that new questions have been posted
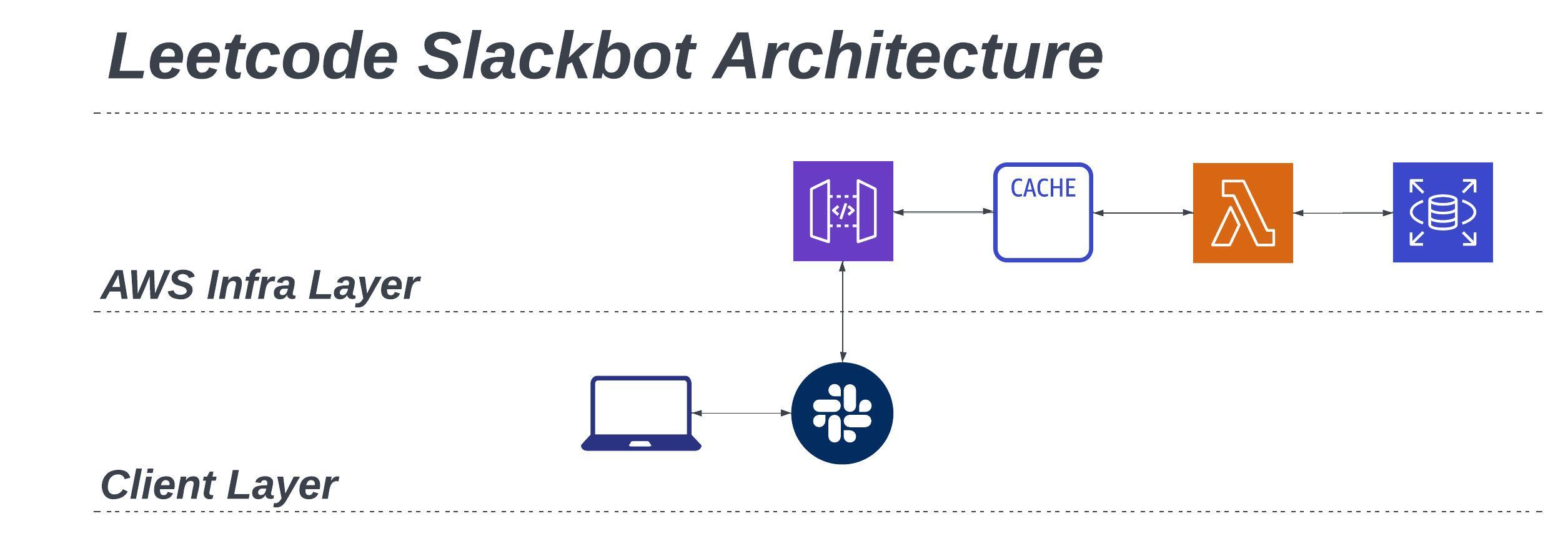
The second part of the architecture is the Slackbot, and questions are retrieved via Slack slash commands as follows:
- User queries the problem set in Slack with slash commands -
/random,/{company_name},/{problem_type},/new, or/{problem_id} - POST request with the given slash command is sent to API Gateway
- Check cache to see if response has been cached and return cache if exists
- If not cached, execute AWS Lambda function to run SQL query in RDS
- Return response to Slack and cache response
- Format response in a human-friendly format using Slack Block Kit
- Slackbot posts formatted response as a reply to the slash command query
Challenges
The first obvious challenge for me was not being familiar with my chosen tech stack. It took some time to ramp up and to get things configured with the Python toolchain, mainly because I'd get my environment mixed up with Python 2.x and 3.x. It's a bit of a gotcha, but overall the Python community community support is as strong as any other community I've encountered in software.
On the actual project, one of the first issues I ran into was that the LeetCode website didn't render all of the html elements immediately upon request. That would cause the crawler to return incomplete data, if any. The brute force way I got around this was to request the page and wait some time before I checked for specific html elements and attributes.
Another issue I ran into was making too many requests in a short period of time, leading to my IP address getting flagged. To get around this, I implemented a few things - randomized user-agent rotation, IP address rotation, and reduced the requests at a randomized interval between 30 and 60 seconds. It wasn't a silver bullet as I still hit some walls, but was eventually able to find a combination that worked.
One of the biggest bottlenecks was implementing the extraction as depth-first search. I built the scraper to login, visit the problem set page, and then navigate to the next available href or paginate to the next page if available. Once the data was extracted from the problem, I'd navigate back to problem list and then move to the next available href.
If I Could Do It All Over Again
In retrospect, I think a more scalable approach would be to grab each single available href and implement a worker queue to do breadth-first search. I'd imagine it would be much easier to approach this concurrently if I just enqueued and dequeued urls to process, and I'd also be able to randomize the user-agent and IP address at this step. I envision being able to iterate over the queue and spin off concurrent workers since each problem is independent and doesn't depend on another.
In hindsight, the return order doesn't matter since the original order could be kept by problem id, so I think optimizing for concurrency would be the right choice here. Making these changes to the arhictecture would increase scalability and decrease the overall run time of the script significantly.
Another thing I'd investigate is going another url down and grab the comments and language implementations for each problem. It would be interesting to note how each programming language compared to each other.
Final Thoughts
I worked on this project in my free time over the course of a few weeks and I learned a ton about webcrawling, data ETL, Python, AWS cloud infrastructure, and more. This was a good stretch project that pushed me in areas I was not very experienced in.
Python is a fantasic tool for the job because of developer velocity, standard and third-party library support, easy integration with AWS, and it has such a strong community around it. I think the major tradeoffs here are that, due to it being an interpreted language, its performance is on the slower side and bugs can be more difficult to track down.
I found the AWS services (API Gateway, Lambda, S3, and RDS) relatively easy-ish to build and deploy, thanks to extensive resources and first-class support for Python. Scaling vertically and horizontally are made easy, and other key parts of the infrastructure is abstracted away to support scaling (e.g., caching in API Gateway was as simple as a click of a button). I found AWS to be approachable as someone who didn't have any cloud infrastructure experience.
All in all, this project provided an opportunity to learn more about a tech stack and domain I was mostly unfamiliar with. Through webcrawling, I automated a workflow that was a very manual and time-consuming process for my study group and allowed us a way to collaborate with much less friction.
I really enjoyed the challenge of building this, and it coincidentally ended up preparing me more for my interviews than practicing LeetCode did. I ended up getting a new job, along with all of the other folks in my study group, so I eventually stopped working on the project. I recently made the dataset available on kaggle where I hope it can help others achieve their goals, also.